Basic Troubleshooting on Ethernet Networks
Network troubleshooting is a repeatable process to identify, test, and resolve issues on a network. Below is a quick FAQ-style guide to the most common tools and the basic steps you can follow.
Common Network Troubleshooting Tools
- Switch Logs
Record topology changes, link loss, PoE failures, errors and reboots. On EtherWAN switches, logs are available via both CLI and GUI.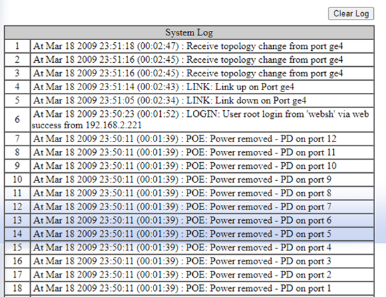
System log view (topology change / PoE events) - Ping
Verifies IP reachability and measures round-trip time. Good quick check for IP routing, Layer-2 path, and basic cabling.- Tells you: routing/L2 path is up, fiber/cable likely OK
- Doesn’t tell you: web/SSH/Telnet availability or VLAN correctness
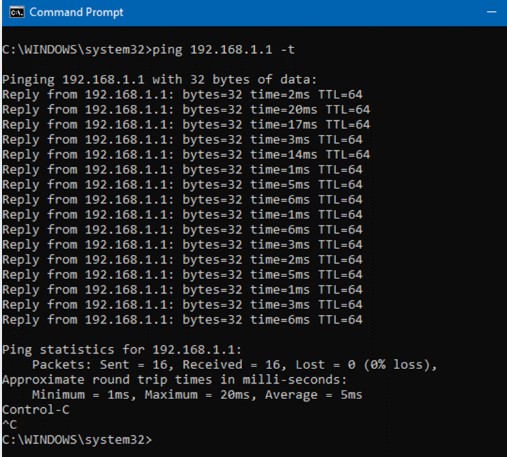
Ping results (latency / reachability) - Traceroute (Windows:
tracert)
Maps the routed path hop-by-hop and latency to each gateway; helps verify inter-VLAN routing and gateway health. Note: L2-only switches won’t appear.
Traceroute path and per-hop time - DDM (Digital Diagnostic Monitoring)
From SFP/optical modules: mode, wavelength, length, temperature, TX/RX power; raises alarms for over-temp, LOS, laser faults (EtherWAN: web GUI).
Optical link health (DDM) - eVue (EtherWAN Network Monitoring)
Discovers EtherWAN devices, visualizes topology, and notifies by email/SMS by severity. Centralizes multi-device monitoring across LAN/WAN.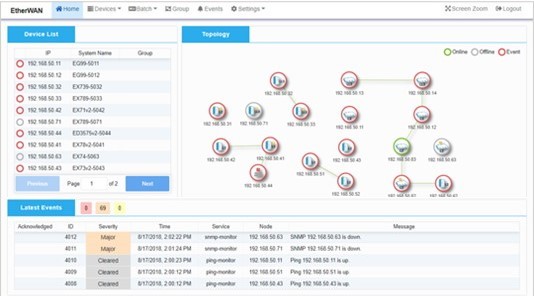
eVue topology and events
Pro Tip
Start simple: Ping → Traceroute → Logs → DDM. Correlate with recent changes. For ongoing visibility, onboard devices into eVue to keep topology and events up to date.
Basic Troubleshooting Steps
- Identify the Problem — Ask users, capture symptoms, and note what changed just before the issue.
- List Probable Causes — Power, environment, subnets, servers, security; order from most to least likely.
- Test the Causes — Use Ping/Traceroute/Logs/DDM to confirm or eliminate each hypothesis.
- Create a Plan — Apply the fix; for complex cases, write out the steps and rollback.
- Verify & Prevent — Confirm service is restored; add guards (alerts, config checks) to avoid repeats.
- Document — Record findings, actions, and outcomes for future reference.
A structured approach is faster than guesswork. Combine these tools with a clear process, and consider eVue for continuous monitoring and faster mean-time-to-repair.